The replication is using MD5 file checks together with CRCs to detect object issues
When objects are stored in S3 using the API, a HTTP 200 OK response is provided
Billing:
GB/month of data stored in S3
A dollar for GB charge transfer out (in is free)
Price per 1000 requests
No specific retrieval fee, no minimum duration, no minimum size
S3 standard makes data accessible immediately, can be used for static website hosting
Should be used for data frequently accessed
S3 Standard-IA:
Shares most of the characteristics of S3 standard: objects are replicated in 3 AZs, durability is the same, availability is the same, first byte latency is the same, objects can be made publicly available
Billing:
It is more cost effective for storing data
Data transfer fee is the same as S3 standard
Retrieval fee: for every GB of data there is a retrieval fee, overall cost may increase with frequent data access
Minimum duration charge: we will be billed for a minimum of 30 days, minimum capacity of the objects being 128KB (smaller objects will be billed as being 128 KB)
Should be used for long lived data where data access is infrequent
S3 One Zone-IA:
Similar to S3 standard, but cheaper. Also cheaper than S3 standard IA
Data stored using this class is only stored in one region
Billing:
Similar to S3 standard IA: similar minimum duration fee of 30 days, similar billing for smaller objects and also similar retrieval fee per GB
Same level of durability (if the AZ does not fail)
Data is replicated inside one AZ
Since data is not replicated between AZs, this storage class is not HA. It should be used for non-critical data or for data that can be reproduced easily
S3 Glacier Instant Retrieval:
It like S3 Standard-IA, but with cheaper storage, more expensive retrieval, longer minimums
Recommended for data that is infrequently accessed (once per quarter), but it still needs to be retrieved instantly
Minimum storage duration charge is 90 days
S3 Glacier Flexible Retrieval (formerly knowns as S3 Glacier):
Same data replication as S3 standard and S3 standard IA
Same durability characteristics
Storage cost is about 1/6 of S3 standard
S3 objects stored in Glacier should be considered cold objects (should not be accessed frequently)
Objects in Glacier class are just pointers to real objects and they can not be made public
In order to retrieve them, we have to perform a retrieval process:
A job that needs to be done to get access to objects
Retrievals processes are billed
When objects are retrieved for Glacier, they are temporarily stored in standard IA and they are removed after a while. We can retrieve them permanently as well
Retrieval job types:
Expedited: objects are retrieved in 1-5 minutes, retrieval process being the most expensive
Standard: data is accessible at 3-5 hours
Bulk: data is accessible at 5-12 hours at lower cost
Glacier has a 40KB minimum billable size and a 90 days minimum duration for storage
Glacier should be used for data archival (yearly access), where data can be retrieved in minutes to hours
S3 Glacier Deep Archive:
Deep Archive represents data in a frozen state
Has a 40KB minimum billable data size and a 180 days minimum duration for data storage
Objects can not be made publicly available, data access is similar to standard Glacier class
Restore jobs are longer:
Standard: up to 12 hours
Bulk: up to 48 hours
Should be used for archival which is very rarely accessed
S3 Intelligent-Tiering:
It is a storage class containing 5 different tiering a storage
Objects that are access frequently are stored in the Frequent Access tier, less frequently accessed objects are stored in the Infrequent Access tier. Objects accessed very infrequently will be stored in either Archive or Deep Archive tier
We don’t have to worry for moving objects over tier, this is done by the storage class automatically
Intelligent tier can be configured, archiving data is optional and can be enabled/disabled
There is no retrieval cost for moving data between frequent and infrequent tiers, we will be billed based on the automation cost per 1000 objects
S3 Intelligent-Tiering is recommended for unknown or uncertain data access usage
Storage classes comparison:
S3 Standard
S3 Intelligent-Tiering
S3 Standard-IA
S3 One Zone-IA
S3 Glacier Instant
S3 Glacier Flexible
S3 Glacier Deep Archive
Designed for durability
99.999999999% (11 9’s)
99.999999999% (11 9’s)
99.999999999% (11 9’s)
99.999999999% (11 9’s)
99.999999999% (11 9’s)
99.999999999% (11 9’s)
99.999999999% (11 9’s)
Designed for availability
99.99%
99.9%
99.9%
99.5%
99.9%
99.99%
99.99%
Availability SLA
99.9%
99%
99%
99%
99%
99.9%
99.9%
Availability Zones
≥3
≥3
≥3
1
≥3
≥3
≥3
Minimum capacity charge per object
N/A
N/A
128KB
128KB
128KB
40KB
40KB
Minimum storage duration charge
N/A
30 days
30 days
30 days
90 days
90 days
180 days
Retrieval fee
N/A
N/A
per GB retrieved
per GB retrieved
per GB retrieved
per GB retrieved
per GB retrieved
First byte latency
milliseconds
milliseconds
milliseconds
milliseconds
milliseconds
select minutes or hours
select hours
Storage type
Object
Object
Object
Object
Object
Object
Object
Lifecycle transitions
Yes
Yes
Yes
Yes
Yes
Yes
Yes
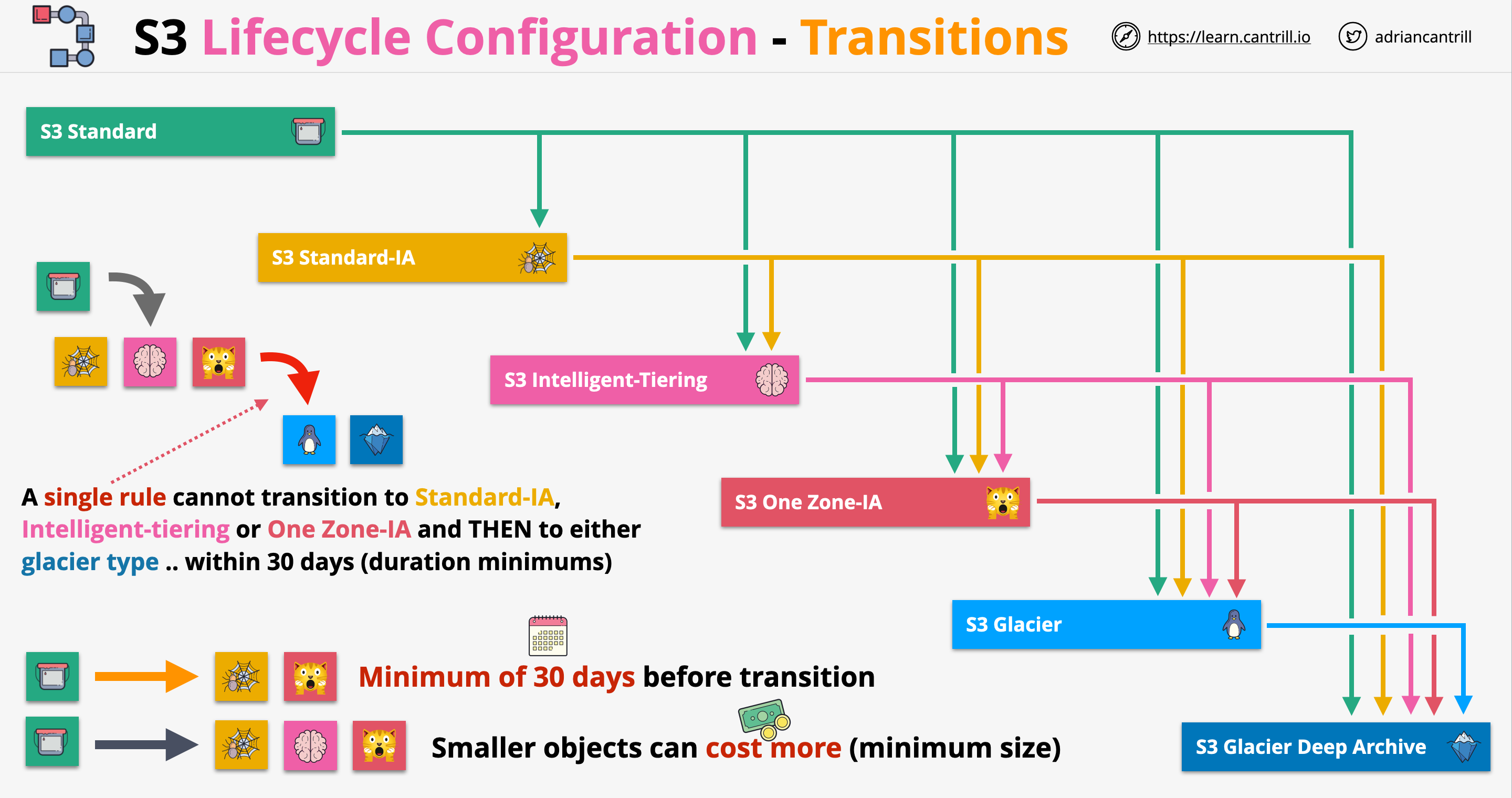
S3 Lifecycle Configuration
We can create lifecycle rules on S3 buckets which can move objects between tiers or expire objects automatically
A lifecycle configuration is a set of rules applied to a bucket or a group of objects in a bucket
Rules consist of actions:
Transition actions: move objects from one tier to another after a certain time
Expiration actions: delete objects or versions of objects
Objects can not be moved based on how much they are accessed, this can be done by the intelligent tiering. We can move objects based on time passed
By moving objects from one tier to another we can save costs, expiring objects also will help saving costs
Transitions between tiers:
Considerations:
Files from One Zone-IA can transition to Glacier Flexible, or Deep Archive, NOT into Glacier Instant retrieval
Smaller objects cost more in Standard-IA, One Zone-IA, etc.
An object needs to remain for at least 30 days in standard tier before being able to be moved to infrequent tiers (objects can be uploaded manually in infrequent tiers)
A single rule can not move objects instantly from standard IA to infrequent tiers and then to Glacier tiers. Objects have to stay for at least 30 days in infrequent tiers before being able to be moved by one rule only. In order ot overcome this, we can define 2 different rules
S3 Replication
2 types of replication are supported by S3:
Cross-Region Replication (CRR)
Same-Region Replication (SRR)
Both types of replication support same account replication and cross-account replication
If we configure cross-account replication, we have to define a policy on the destination account to allow replication from the source account
We can create replicate all objects from a bucket or we can create rules for a subset of objects. We can filter objects to replicate based on prefix or tags or both
We can specify which storage class to use for an object in the destination bucket (default: use the same class)
We can also define the ownership of the objects in the destination bucket. By default it will be the same as the owner in the source bucket
Replication Time Control (RTC): if enabled ensures a 15 minutes replication of objects
Replication consideration:
By default replication is not retroactive: only newer objects are replicated after the replication is enabled
Versioning needs to be enabled for both source and destination buckets
Batch replication can be used to replicate existing objects. It needs to be specifically configured. If it is not, replication wont be retroactive
Replication by default one-way only, source => destination. There is an option to use bi-directional replication, but this has to be configured
Replication is capable of handling objects encrypted with SSE-S3 and SSE-KMS (with extra configuration). SSE-C (customer managed keys) is also supported, historically it was incompatible
Replication requires for the owner of source bucket needs permissions on the objects which will be replicated
System events will not be replicated, only user events
Any objects in the Glacier and Glacier Deep Archive will not be replicated
By default, deletion are not replicated. We can enable replication for deletion events
Replication use cases:
SRR:
Log aggregation
PROD and Test sync
Resilience with strict sovereignty
CRR
Global resilience improvements
Latency reduction
S3 Encryption
Buckets aren’t encrypted, objects inside buckets are encrypted
Encryption at rest types:
Client-Side encryption: data is encrypted before it leaves the client
Server-Side encryption: data is encrypted at the server side, it is sent on plain-text format from the client
Both encryption types use encryption in-transit for communication
Server-side encryption is mandatory, we cannot store data in S3 without being encrypted
There are 3 types of server-side encryption supported:
SSE-C: server-side encryption with customer-provided keys
Customer is responsible for managing the keys, S3 managed encryption/decryption
When an object is put into S3, we need to provide the key utilized
The object will be encrypted by the key, a hash is generated and stored for the key
The key will be discarded after the encryption is done
In case of object retrieval, we need to provide the key again
SSE-S3 (default): server-side encryption with Amazon S3-managed keys
AWS handles both the encryption/decryption and the key management
When using this method, S3 creates a master key for the encryption process (handled entirely by S3)
When an object is uploaded an unique key is used for encryption. After the encryption, this unique key is encrypted as well with the master key and the unencrypted key is discarded. Both the key and the object are stored together
For most situations, this is the default type of encryption. It uses AES-256 algorithm, they key management is entirely handled bt S3
SSE-KMS: Server-side encryption with customer-managed keys stored in AWS Key Management Service (KMS)
Similar to SSE-S3, but for this method the KMS handles stored keys
When an object is uploaded for the first time, S3 will communicate with KMS and creates a customer master key (CMK). This is default master key used in the future
When new objects are uploaded AWS uses the CMK to generate individual keys for encryption (data encryption keys). The data encryption key will be stored along with the object in encrypted format
We don’t have to use the default CMK provided by AWS, we can use our own CMK. We can control the permission on it and how it is regulated
SSE-KMS provides role separation:
We can specify who can access the CMK from KMS
Administrators can administers buckets but they may not have access to KMS keys
Default Bucket Encryption:
When an object is uploaded, we can specify which server-side encryption to be used by adding a header to the request: x-amz-server-side-encryption
Values for the header:
To use SSE-S3: AES256
To use SSE-KMS: aws:kms
All Amazon S3 buckets have encryption configured by default, and all new objects that are uploaded to an S3 bucket are automatically encrypted at rest
Server-side encryption with Amazon S3 managed keys (SSE-S3) is the default encryption configuration for every bucket in Amazon S3, this can be overridden in a PUT request with x-amz-server-side-encryption header
S3 Bucket Keys
Each object in a bucket is using a uniq data-encryption key (DEK)
AWS uses the bucket’s KMS key to generate this data-encryption key
Calls to KMS have a cost and levels where throttling occurs: 5500/10_000/50_000 PUT/sec depending on region
Bucket keys:
A time limited bucket key is used to generate DEKs within S3
KMS generates a bucket key and gives it to S3 to use to generate DEKs for each upload, offloading the load from KMS to S3
Reduces the number of KMS API calls => reduces the costs/increases scalability
Using bucket keys is not retroactive, it will only affect objects after bucket keys are enabled
Thing to keep in mind after enabling bucket keys:
CloudTrail KMS event logs will show the bucket ARN instead of the object ARN
Fewer CloudTrail events of KMS will be in the logs (since work is offloaded to S3)
Bucket keys work with SRR and CRR; the object encryption settings are maintained
If we replicate plaintext to a bucket using bucket keys, the object is encrypted at the destination side; this can result in ETAG changes on the object
S3 Presigned URLs
Is a way to give other people access to our buckets using our credentials
An IAM admin can generate a presigned URL for a specific object using his credentials. This URL will have an expiry date
The presigned URL can be given to unauthenticated uses in order to access the object
The user will interact with S3 using the presigned URL as if it was the person who generated the presigned URL
Presigned URLs can be used for downloads and for uploads
Presigned URLs can be used for giving direct access private files to an application user offloading load from the application. This approach will require a service account for the application which will generate the presigned URLs
Presigned URL considerations:
We can create a presigned ULR for objects we don’t have access to
When using the URL, the permissions match the identity which generated it. The permissions are evaluated at the moment of accessing the object (it might happen the the identity had its permissions revoked, meaning we wont have access to the object either)
We should not generate presigned URLs generated on temporary credentials (assuming an IAM role). When the temporary credentials are expired, the presigned URL will stop working as well. Recommended to use long-term identities such as an IAM user
S3 Select and Glacier Select
Are ways to retrieve parts of objects instead of entire objects
S3 can store huge objects (up to 5 TB)
Retrieving a huge objects will take time and consume transfer capacity
S3/Glacier provides services to access partial objects using SQL-like statements to select parts of objects
Both S3 Select and Glacier selects supports the following formats: CSV, JSON, Parquet, BZIP2 compression for CSV and JSON
S3 Access Points
Improves the manageability of objects when buckets are used for many different teams or they contain objects for a large amount of functions
Access Points simplify the process of managing access to S3 buckets/objects
Rather than 1 bucket (1 bucket policy) access we can create many access points with different policies
Each access point can be limited from where it can be accessed, and each can have different network access controls
Each access point has its own endpoint address
We can create access point using the console or the CLI using aws s3control create-access-point --name < name > --account-id < account-id > --bucket < bucket-name >
Any permission defined on the access point needs to be defined on the bucket policy as well. We can do delegation, by defining wide access permissions in the bucket policy and granular permissions on the access point policy
S3 Block Public Access
The Amazon S3 Block Public Access feature provides settings for access points, buckets, and accounts to help manage public access to Amazon S3 resources
The settings we can configure with the Block Public Access Feature are:
IgnorePublicAcls: this prevents any new ACLs to be created or existing ACLs being modified which enable public access to the object. With this alone existing ACLs will not be affected
BlockPublicAcls: Any ACLs actions that exist with public access will be ignored, this does not prevent them being created but prevents their effects
BlockPublicPolicy: This prevents a bucket policy containing public actions from being created or modified on an S3 bucket, the bucket itself will still allow the existing policy
RestrictPublicBuckets: this will prevent non AWS services or authorized users (such as an IAM user or role) from being able to publicly access objects in the bucket
S3 Cost Saving Options
S3 Select and Glacier Select: save in network a CPU cost by retrieving ony the necessary data
S3 Lifecycle Rules: transition objects between tiers
Compress objects to save space
S3 Requester Pays:
In general, bucket owners pay for all Amazon S3 storage and data transfer costs associated with their bucket
With Requester Pays buckets, the requester instead of the bucket owner pays the cost of the request and the data download from the bucket
The bucket owner always pays the cost of storing data
Helpful when we want to share large datasets with other accounts
Requires a bucket policy
If an IAM role is assumed, the owner account of that role pays for the request!
S3 Object Lock
Object Lock can be enabled on newly created S3 buckets. For existing ones in order to enable Object Lock we have to contact AWS support
Versioning will be also enabled when Object Lock is enabled
Object Lock can not be disabled, versioning can not be suspended when Object Lock is active on the bucket
Object Lock is a Write-Once-Read-Many (WORM) architecture: when an object is written, can not be modified. Individual versions of objects are locked
There are 2 ways S3 managed object retention:
Retention Period
Legal Hold
Object versions can have both retention period and legal hold enabled; can have only one of those enabled or none of them
Object Lock retentions can be individually defined on object versions, a bucket can have default Object Lock settings
Retention Period
When a retention period is enabled on an object, we specify the days and years for the period
The retention period will end after the period
There are 2 types of retention period modes:
Compliance mode:
Object can not be adjusted, deleted or overwritten. The retention period can not be reduced, the retention mode can not be adjusted even by the account root user
Should be used for compliance reasons
Governance mode:
Objects can not be adjusted, deleted or overwritten, but special permissions can be added to some identities to allow for the lock setting to be adjusted
This identities should have the s3:BypassGovernanceRetention permission
The governance mode can be overwritten when passing x-amz-bypass-governance-retention:true header (header is default for console ui)
Legal Hold
We don’t set a retention period for this type of retention, Legal Hold can be on or off for specific versions of an object
We can’t delete or overwrite an object with Legal Hold
An extra permission is required when we want to add or remove the Legal Hold on an object: s3:PutObjectLegalHold
Legal Hold can be used for preventing accidental removals
S3 Transfer Accelerate
Used to transfer files into S3. Enables fast, easy, and secure transfers of files over long distances between our client and an S3 bucket
Takes advantage of the globally distributed edge locations in Amazon CloudFront
We might want to use Transfer Acceleration on a bucket for various reasons:
We upload to a centralized bucket from all over the world
We transfer gigabytes to terabytes of data on a regular basis across continents
We can’t use all of our available bandwidth over the internet when uploading to Amazon S3
To use Transfer Accelerate, it must be enabled on the bucket. After we enable Transfer Acceleration on a bucket, it might take up to 20 minutes before the data transfer speed to the bucket increases
S3 Object Lambda
With Amazon S3 Object Lambda, we can add our own code to Amazon S3 GET, LIST, and HEAD requests to modify and process data as it is returned to an application
S3 Object Lambda uses AWS Lambda functions to automatically process the output of standard S3 GET, LIST, or HEAD requests
After we configure a Lambda function, we attach it to an S3 Object Lambda service endpoint, known as an Object Lambda Access Point
The Object Lambda Access Point uses a standard S3 access point
When we send a request to your Object Lambda Access Point, Amazon S3 automatically calls your Lambda function
Hosting Static Site on S3
We can host a static site on S3
To host a static site in a bucket we must enable static website hosting, configure an index document, and set permissions
We should also make a bucket content public:
We should turn of Block Public Access settings
We should attach a bucket policy which allows public read on the objects
Amazon S3 website endpoints do not support HTTPS! If we want to use HTTPS, we can use Amazon CloudFront to serve a static website hosted on Amazon S3