Provide the ability to implement a self-healing architecture
ASGs make use of configurations defined in launch templates or launch configurations
ASGs are using one version of a launch template/configuration
ASG have 3 important values defined: Minimum, Desired and Maximum size. Desired size has to be more than the minimum size and less than Maximum size.
ASG provides on foundational job: keeps the size of running instances at the desired size
Archechturally ASG define where the EC2 instances are launcehd. They are attcahed to VPC and which subnets are configured within the VPC in ACG.
Scaling Policies: update the desired capacity based on some metric (CPU usage, number of connections, etc.)
They are essentially rules defined by us which can adjust the values of an ASG
Scaling policies are used with ASG.
Scaling types:
Manual Scaling : Manually adjusts the desired capcacity.
Scheduled Scaling: Scheduling based on know time window
Dynamic Scaling
Predictive Scaling: scale based on historical load to detect patterns in traffic flows
Dynamic Scaling has 3 subtypes:
Simple Scaling: Based on Metric. Example “CPU above 50% +1”, “CPU Below 50% -1”
Step Scaling: scaling based on difference, allowing to react quicker
Target Tracking: example desired aggregate CPU = 40%. Not all metrics are supported by target tracking scaling
Cooldown Period: a value in seconds, controls how long to wait after a scaling action happened before starting another action
ASG monitor the health of instances, by default using the EC2 health checks
ASG can integrate with load balancers: ASG can add/remove instances from a LB target group
ASG can use the LB health checks in case of EC2 health checks
Scaling Processes
Launch and Terminate: if Launch is suspended, the ASG wont scale out / if Terminate is suspended the ASG wont scale in
AddToLoadBalancer: add instance to LB
AlarmNotification: control is the ASG reacts to CloudWatch alarms
AZRebalance: balances instances evenly across all of AZs
HealthCheck: controls if instance health checks are on/off
ReplaceUnhealthy: controls if instances are replaced in case there are unhealthy
ScheduledActions: controls if scheduled actions are on/off
Standby: suspend any activities of ASG in a specific instance
ASG Consideration
ASG are free, we pay only for the instances provisioned
We should use cool downs to avoid rapid scaling
We should use smaller instances for granularity
ASG integrates with ALBs
ASG defines when and where, LT defines what
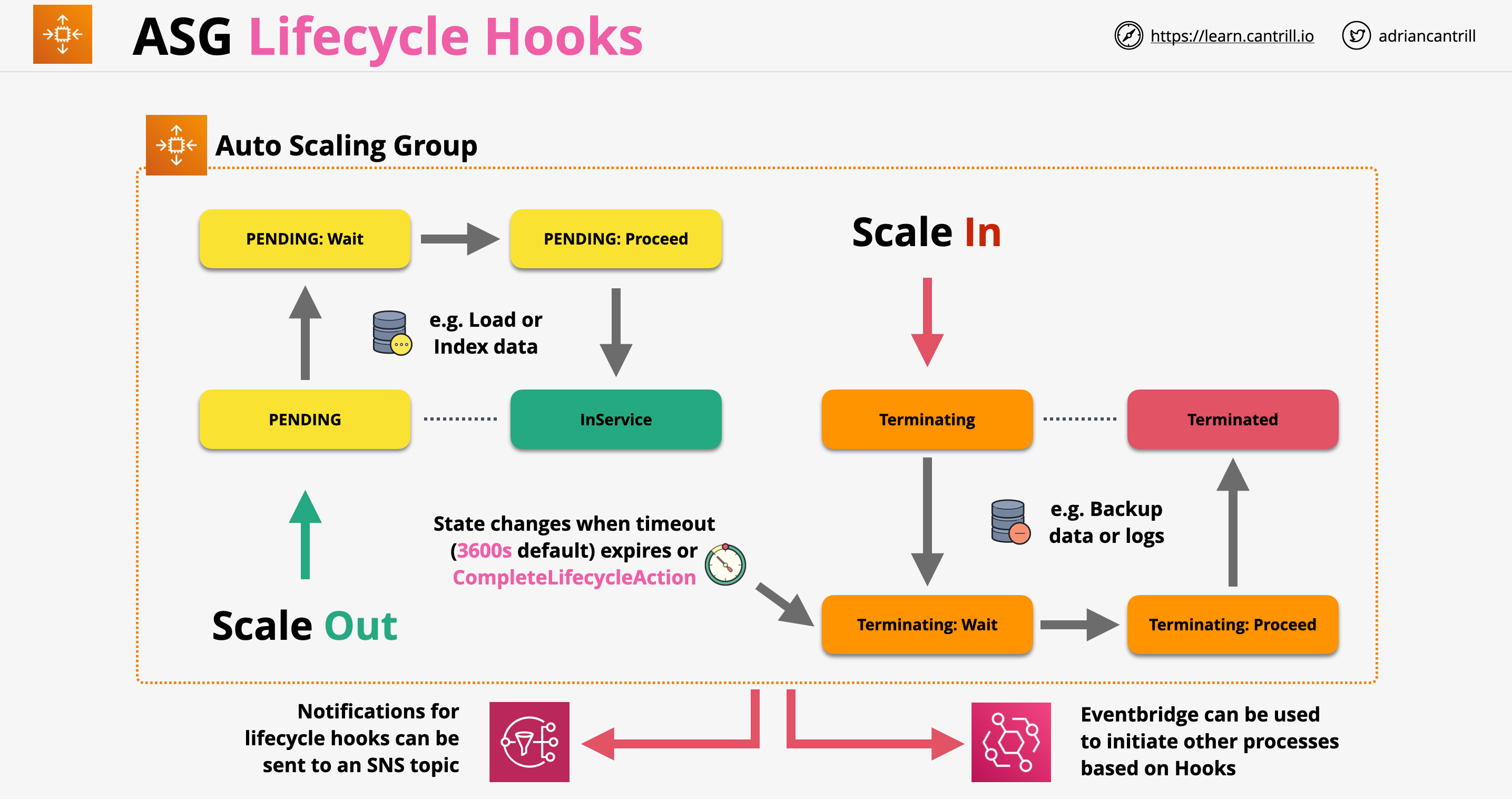
Lifecycle Hooks
Allow to configure custom actions which can occur during ASG actions
When an ASG scales out/in instances may pause within the flow to allow execution of lifecycle hooks
We can specify a timeout (36000s by default) for the lifecycle action, after the pause the system can decide if the ASG process continues or is abandoned
We can resume the ASG process by calling CompleteLifecycleAction
Lifecycle event hooks can be integrated with EventBridge or SNS notifications
Scaling Policies
ASGs don’t need scaling policies, they can work just fine with none
When created without a scaling policy, an ASG has static values for MinSize, MaxSize and Desired capacity
Manual scaling: we manually adjust the values listed before; useful for testing or urgent situations or when we need to hold capacity at fixed number of instances
In addition to manual scaling, we had different types of dynamic scaling policies. Each of these adjusts the desired capacity of an ASG based on a certain criteria
Dynamic scaling policies:
Simple Scaling:
We define action which occur when a alarm goes to ALARM state. For example: add one instance if CPUUtilization is above 40%
Helps infrastructure scale out/in based on demand
This scaling is inflexible, add/remove static number of instances based on the status of an alarm
Step Scaling:
Adjust number of instances based on a number of step adjustments, that wary based on the size of the alarm brige
Example:
If the CPU usage is between 50-60%, do nothing
If the CPU usage is between 60 and 70%, add one instance
If the CPU usage is between 70 and 80%, add two instances
Finally, add 3 instances if the CPU usage is above 80%
Generally is better compared to Simple Scaling, allows us to adjust better to change load patterns
Target Tracking:
Comes with a predefined set of metrics: CPUUtilization, AvgNetworkIn, AvgNetworkOut, AlbRequestCountPerTarget
We define an ideal value, a target we want to track against for a supported metric
The ASG calculates the scaling adjustment based on the metric and the target value
The ASG keeps the metric at the target value we specified and adjusts the capacity as required
Scaling based on SQS - ApproximateNumberOfMessagesVisible:
Scaling is done based on the number of messages currently in the SQS queue
Predictive Scaling:
Predictive scaling uses historical data load to detect patterns in traffic flows and scale accordingly
Needs at least 24 hours of data to work, if available uses the past 14 days of data to analyze patterns
When enabled it will run in forecast only mode, in which no autoscaling action will take place. It will generate capacity forecasts which will allow us to evaluate the accuracy and the suitability of the autoscaling
After we review it, it will switch to forecast and scale mode
Maximum capacity limit: maximum number of EC2 instances that can be launched. We can allow the groups maximum capacity to be automatically increased
A core assumption of predictive scaling is that the Auto Scaling group is homogenous and all instances are of equal capacity. If this isn’t true, forecasted capacity can be inaccurate
AWS recommends using Step Scaling instead of Simple Scaling policy
ASG Health Checks
ASGs assess the health of instances within their group using health checks
If an instance fails health checks, it is replaced within the group => automatic healing
There 3 different types of health checks that can be used by ASGs:
EC2 (default)
ELB (can be enabled)
Custom
With EC2 health checks any of these statuses are viewed as unhealthy: Stopping, Stopped, Terminated, Shutting Down, Impaired (not 2/2 status checks)
With ELB health checks in instance to be viewed as healthy it should be running and it should be passing the ELB health checks
ELB health checks can be more application aware (Layer 7)
Custom health checks: instances can be marked healthy/unhealthy by an external system
Health check grace period:
It is configurable value, by default is 300s
It is a delay before health checks starting to check on a specific instance
Allows system launch, bootstrapping and application start