RDS is often described as a Database-as-a-service (DBaaS) but this is not accurate. It should be named Database Server as a Service (DBSaaS) product
RDS provides managed database instances, which can themselves hold one or more databases
Benefits of RDS are the we don’t need to manage the physical hardware, the server operating system or the database system itself
RDS supports MySQL, MariaDB, PostgreSQL, Oracle, Microsoft SQL Server
Amazon Aurora: it is a db engine created by AWS and we can select it as well for usage
RDS Subnet Group: list of subnets which an RDS database can use. Generally it is best practice to have on Subnet Group per database deployment
RDS Database Instance
Runs one of the few types of db engine mentioned above
Can contain multiple user created databases
A database instance after creation can be accessed using its hostname (CNAME)
RDS instances come in various types, share many of features of EC2. Example of instances: db.m5, db.r5, db.t3
RDS instances can be single AZ or multi AZ (active-passive failover)
When an instance is provisioned, it will have a dedicated storage allocated as well (usually EBS)
Storage allocated can be based on SSD storage (IO1, GP2) or magnetic (mainly for compatibility)
Billing for RDS:
We are billed based on instance size on a hourly rate
We are billed for additional instances used for Multi AZ deployments
We are also billed per storage (GB/month) + extra per iops in case of provisioned iops (IO1)
Data transfer is also billed if data is coming from/goes to the internet/other regions
Backups and snapshots are also billed (per GB per month)
Licensing is applicable is also billed
RDS Multi AZ
They are 2 types of Multi AZ deployments:
Multi AZ Instance (historically called Multi AZ)
Multi AZ Cluster
Multi AZ Instance:
Used to add resilience to an RDS instance
Replication happens at the storage level
Enables synchronous replication between primary and standby instances
Multi AZ is an option which can be enabled on an RDS instance, when enabled secondary hardware is allocated in another AZ (standby replica)
RDS is accessed via provided endpoint address (CNAME)
With a single instance the endpoint address points the instance itself, with multi AZ, by default the endpoint points to the primary instance
We can not directly access the standby instance
If an error occurs with the primary instance, RDS automatically changes the endpoint to point to the standby replica. This failover occurs in around 60-120 seconds
Multi AZ is not available in the Free-tier (generally costs double as it would the single AZ)
Backups are taken from the standby instance (removes performance impact)
In case of a failover the DNS name will be updated to point to the standby replica instance. Since this is a DNS change, for the update it generally takes between 60-120 seconds to occur. This can be lessened by removing DNS caching in the application
With Multi AZ instance we have ONE standby replica. This replica cannot be used for read and writes. It waits for a failover to happen and then it can be used
Backups can be taken from the standby instance to improve performance
Failovers can happen if:
AZ outage
Primary instance failure
Manual failover
Instance type change
Software patching
Multi AZ Cluster:
RDS is capable of having one writer replicate to two reader instances. We can have 2 readers only!
These readers are in different AZs compared to the writer
Compared two Aurora cluster mode, Multi AZ cluster can have 2 readers only, while Aurora Cluster can have more
In case of Multi AZ cluster the instances to which data is replicated are usable, compared to Multi AZ instance mode when they are not
In terms of replication the data is viewed as committed when one of the readers confirms that it was written
Other comparisons two Aurora Cluster:
In RDS multi AZ cluster each instance has its own storage, in case of Aurora this is not the case
Like Aurora, the cluster can be accessed with multiple endpoints:
Cluster endpoint: database CNAME, points to the writer, can be used for reads/writes and administration
Reader endpoint: points to any available endpoint for reads (it can point to the writer instance in certain cases). Generally it points to the dedicated reader instances
Instance endpoints: each instance gets one endpoint, generally not recommended to be used
Generally Multi AZ Cluster runs on faster hardware: Graviton + local NVME SSD storage. Any writes are written to local super fast storage, after that they are flushed to the EBS
Replications are done via transaction logs => much more efficient then Multi AZ instance. This also allows faster failover: ~35 seconds + any time required to apply the transaction logs
RDS Backups and Restores
RPO (Recovery Point Objective): time between the last working backup and the failure. Lower the RPO value, usually the more expensive the solution
RTO (Recovery Time Objective): time between the failure and system being fully recovered. Can be reduced with spare hardware, predefined processes, etc. Lower the RTO value, the system is usually more expensive
RDS backup types:
Manual snapshots:
Have to be run manually, or via a script
First snapshot is full content of the DB, incremental onward
When any snapshot occurs, there is brief interruption in the flowing of data between the compute resource and the storage (no noticeable effect in case of Multi AZ, since the backup is taken from the standby instance)
Manual snapshots do not expire
When we delete an RDS instance, AWS offers to make one final snapshot
Automatic backups:
They occur once per day (backup window is defined on the instance)
Snapshots which occur automatically, first being full snapshot, incremental afterwards
In addition to the automated snapshots, every 5 minute transaction logs are written to S3
Automatic backups are not retained, we can set the retention period between 0 and 35 days
Automatic backups can be retained after a DB is deleted, but they still expire after the retention period
We can replicate backups to another region: both snapshots and transaction logs can be replicated. Charges apply to cross-region data copy and any storage used in the destination region
Cross-region replication has to be explicitly configured within automated backups
Backups are stored in AWS manages S3 buckets (backups are not visible to us directly in S3) => any data in S3 is regionally resilient
RDS backups are taken from the standby instance in case Multi AZ is enabled
RDS Restores:
RDS creates a new RDS instance when we restore an automated backup or a manual snapshot => new address will be created for the DB
When we restore a snapshot, we restore our DB to a single point in time, when the creation time of the snapshots happened
With automated backups we can chose a point-in-time to where we want to restore (any 5 minute point-in-time)
Restoring snapshots is not a fast procedure (important for RTO)
RDS Read-Replicas
Provide 2 main benefits: performance and availability
Read replicas are read-only replicas of an RDS instance
Read replicas can be used for reading only data
Multi AZ Cluster mode is a similar to how read replicas work, but for read replicas we have to think of read replicas as separate things:
They are not part of the main database instance
They have their own endpoint address
Require application support
There is no automatic failover to a read replica
The primary instance and read replica is kept sync using asynchronous replication
There can be a small amount of lag in case of replication
Read replicas can be created in a different AZ or different region (CRR - Cross-Region Replication)
We can 5 direct read-replicas per DB instance
Each read-replica provides an additional instance of read performance
Read-replicas can also have read-replicas, but lag starts to be a problem in this case
Read-replicas can provide global performance improvements
Snapshots and backups improve RPO but not RTO. Read-replicas offer near 0 RPO
Read-replicas can be promoted to primary in case of a failure. This offers low RTO as well (lags of minutes)
Read-replicas can replicate data corruption
Data Security
With all the RDS engines we can use encryption in transit (SSL/TLS). This can be set to be mandatory on a per user bases
For encryption at rest RDS supports EBS volume encryption using KMS which is handled by the host EBS and it is invisible for the database engine
We can use customer managed or AWS generated CMK data keys for encryption at rest
Storage, logs and snapshots will be encrypted with the same customer master key
Encryption can not be removed after it is activated
In addition to encryption at rest MSSQL and Oracle support TDE (Transparent Data Encryption) - encryption at the database engine level
Oracle supports TDE with CloudHSM, offering much stronger encryption
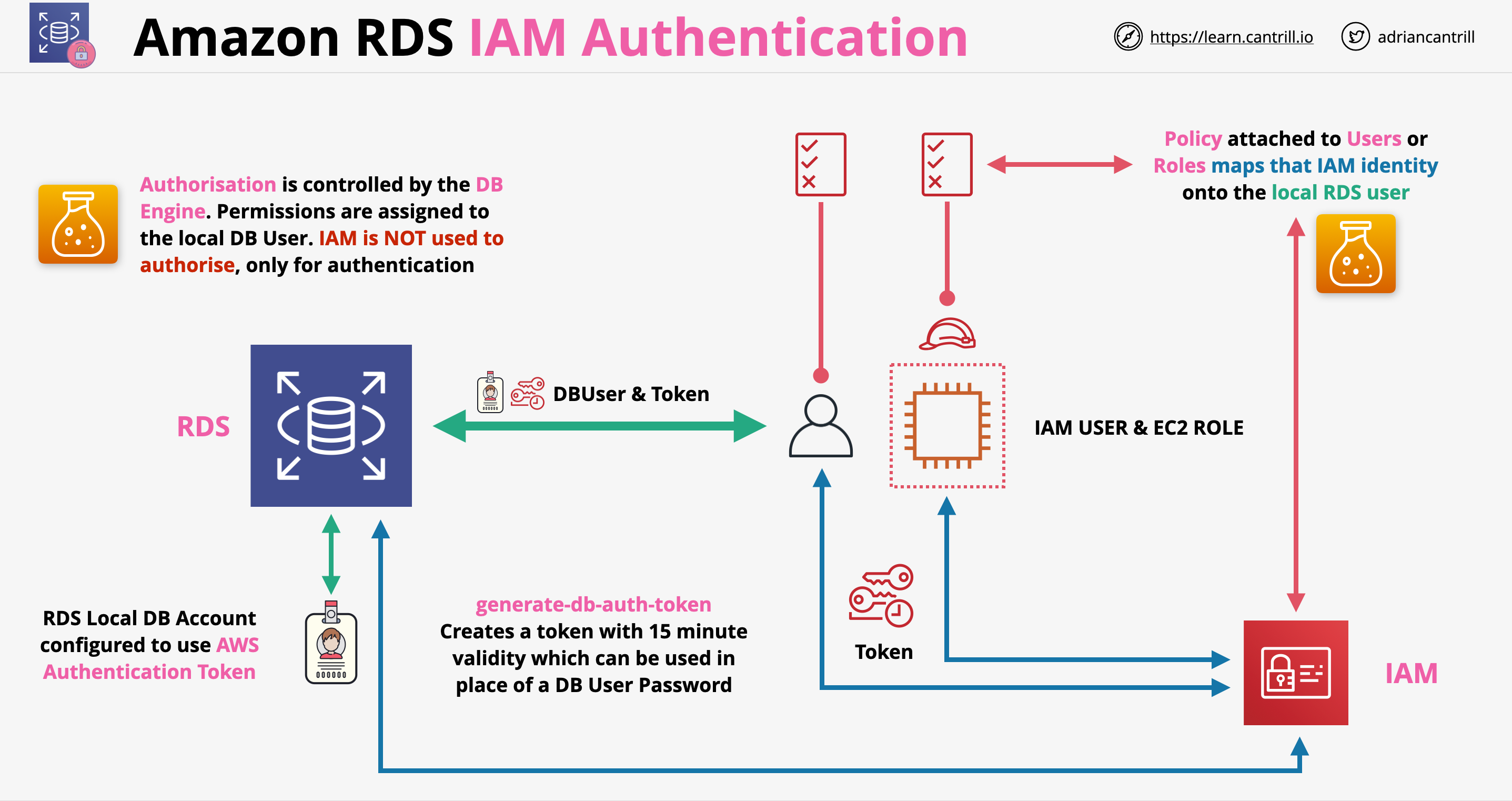
IAM authentication with RDS:
Normally login is controlled with local database users (username/password)
We can configure RDS to allow IAM authentication (only authentication, not authorization, authorization is handled internally!):
RDS Proxy
Opening and closing connections consumes resources and takes time => in case we only want to read/write a tiny amount of data the overhead of establishing a connection creates a significant latency
Handling failure of databases instances is hard, this adds significant overhead and risks to our application
DB proxies can help, but managing them is not always trivial (scaling, resilience)
In case of an RDS proxy our application connects to the proxy, which handles connection polling and connectivity to the database
RDS proxies provide multiplexing: a smaller number of connections can be used to connect to the database while having a larger number of applications using the database through the proxy. This helps to reduce the load on the database
RDS Proxy can help with database failover events abstracting this from the applications. The proxy can wait until a healthy database instance is in place and can automatically connect to it
When to use RDS proxy?
In case we have errors such as Too many connections. An RDS proxy can reduce the number of connections to the dabase while being able to handle many more connections from the applications to itself
Useful when using AWS Lambda, we won’t need to invoke a new connection after each invocation of our function. Saves time by connection reuse and IAM auth
Useful for long running applications (SAAS apps) by reducing latency
RDS Proxy key facts:
Fully managed by RDS/Aurora
By default provides auto scaling, HA
Provides connections pooling, which reduces DB load
Only accessible from a VPC, not accessible from the public internet
Accessed via Proxy Endpoint
Can enforce SSL/TLS connection
Can reduce failover time by over 60% in case of Aurora
Abstracts the failure of a database away for our application
RDS Custom
Fills the gap between the main RDS product and EC2 running a DB engine
The main RDS is fully managed database service => OS/Engine access is limited
In contrast databases running on EC2 are self managed, this can have significant management overhead
RDS custom bridges this gap, we can utilize RDS but still get access to customization we would have when running a DB instance on EC2
Currently RDS custom works from MSSQL or Oracle
We can connect to the underlying OS using SSH, RDP or Session Manager
RDS custom will run withing our AWS account. Classic RDS will run in an AWS managed environment
If we need to perform RDS customization for RDS Custom, we need to look inside the Database Automation settings to make sure we wont have any disruption caused by the Database Automation. We need to pause Database Automation for this period