Managed compute service commonly used for large scale data analytics and processing
It is managed batch processing product
Batch Processing: jobs that can run without end-user interaction, or can be scheduled to run as resources permit
AWS Batch lets us worry about defining jobs, it will handle the underlying compute and orchestration
AWS Batch core components:
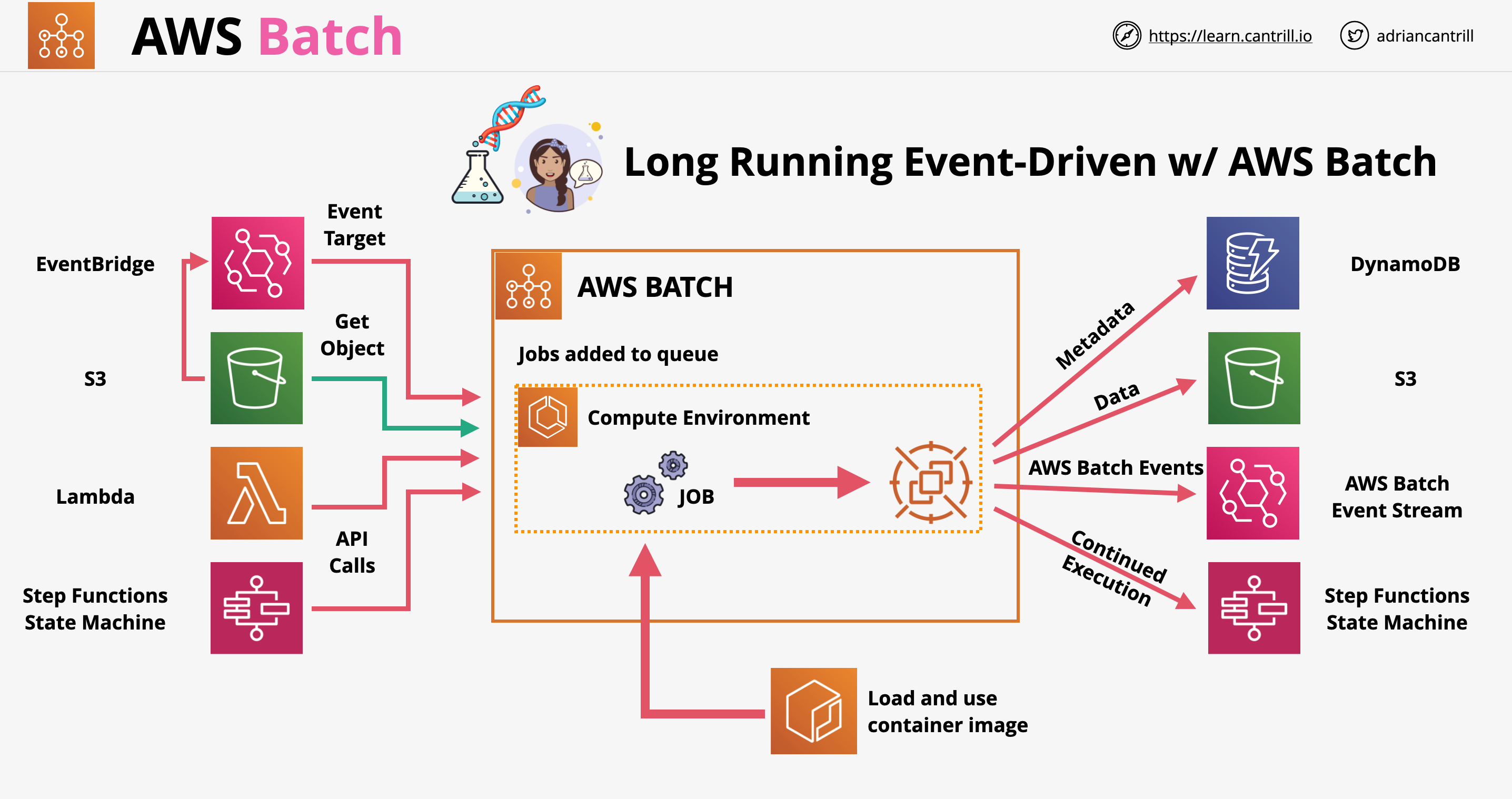
Job: script, executable, docker container submitted to batch. Jobs are executed using containers in AWS. The job define the work. Jobs can depend on other jobs
Job Definition: metadata for a job, including IAM permissions, resource configurations, mount points, etc.
Job Queue: jobs are submitted to a queue, where they wait for compute environment capacity. Queues can have a priority
Compute Environment: the compute resources which do the actual work. Can be managed by AWS or by ourselves. We can configure the instance type, vCPU amount, spot price, or provide details on a compute environment we manage (ECS)
Integration with other services:
AWS Batch vs Lambda
Lambda has a 15 minutes execution limit, for longer workflows we should use Batch
Lambda has limited disk space in the environment, we can fix this by using EFS, but this would require the function to be run inside of a VPC
Lambda is fully serverless with limited runtime selection
Batch is not serverless, it uses Docker with any runtime
Batch does not have a time limit for execution
Managed vs Unmanaged AWS Batch
Managed:
AWS Batch manages capacity based on our workload needs
We decide the instance type/size and if we want to use on-demand or spot instances
We can determine our own max spot price
We need to create VPC gateways for access to the resources
Using the managed compute environment we allow AWS the manage all the infra on our behalf, we just need to tweak some high level values
Unmanaged:
We manage everything, we create the environment, we direct AWS to use that environment
Generally used if we have a full compute environment ready to go