Is a framework designed to allow processing huge amount of data in a parallel, distributed way
Data Analysis Architecture: huge scale, parallel processing
MapReduce has two main phases: map and reduce
It also has to optional phases: combine and partition
At high level the process of map reduce is the following:
Data is separated into splits
Each split can be assigned to a mapper
The mapper perform the operation at scale
The data is recombined after the operation is completed
HDFS (Hadoop File System):
Traditionally stored across multiple data nodes
Highly fault-tolerant - data is replicated between nodes
Named Nodes: provide the namespace for the file system and controls access to HDFS
Block: a segment of data in HDFS, generally 64 MB
Amazon EMR Architecture
Is a managed implementation of Apache Hadoop, which is a framework for handling big data workloads
EMR includes other elements such as Spark, HBase, Presto, Flink, Hive, Pig
EMR can be operated long term, or we can provision ad-hoc (transient) clusters for short term workloads
EMR runs in one AZ only within a VPC using EC2 for compute
It can use spot instances, instance fleets, reserved and on-demand instances as well
EMR is used for big data processing, manipulation, analytics, indexing, transformation, etc.
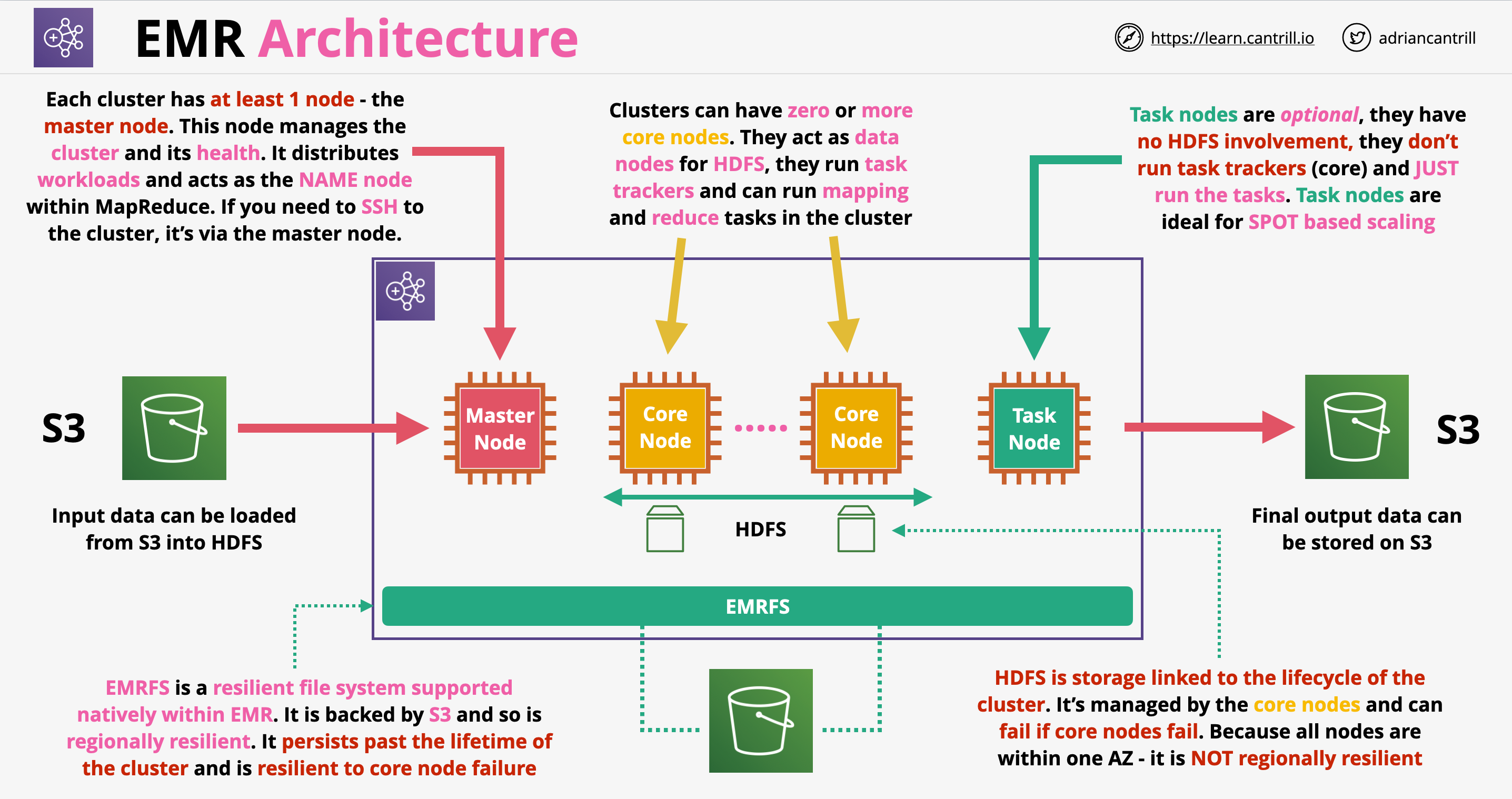
EMR architecture:
Each cluster requires at least one master node. This manages the cluster and distributes workloads and acts as the NAME node within MapReduce (we SSH into this if necessary)
Historically we could have only one master node, nowadays we can have 3 master nodes
Core nodes: cluster can have many core nodes. They are used for tracking task, we don’t want to destroy these nodes
Core nodes also managed to HDFS storage for the cluster. The lifetime of HDFS is linked to the lifetime of the core nodes/cluster
Task nodes: used to only run tasks. If they are terminated, the HDFS storage is not affected. Ideally we use spot instances for task nodes
EMRFS: file system backed by S3, can persist beyond the lifetime of the cluster. Offers lower performance than HDFS, which is based on local volumes
Amazon EMR Serverless
It is a deployment option for Amazon EMR that provides a serverless runtime environment
With EMR Serverless we don’t have to configure, optimize, secure or operate clusters to run applications with frameworks such as Spark and Hive
Job run:
Is a request submitted to an EMR Serverless application that the application asynchronously executes and tracks it until completion
When a job is submitted we must specify an IAM role that will provide required access for the job to other services such as S3
We can submit different jobs at the same time with different runtime roles
Workers:
EMR Serverless internally uses workers to execute our workloads
The default size of this workloads depends on the application type and EMR version
When we submit a job, EMR Serverless computes the resources that the application needs for the job and schedules workers
EMR Serverless automatically scales workers up or down based on the workload and parallelism required at every stage of the job
Pre-initialized capacity:
Used to keep workers initialized and ready to respond in seconds
Effectively creates a warm pool of workers for an application
EMR Studio:
It is the user console where we manage our EMR Serverless applications