It is an OLAP (column based) database, not OLTP (row/transaction)
OLTP (Online Transaction Processing): capture, stores, processes data from transactions in real-time
OLAP (Online Analytical Processing): designed for complex queries to analyze aggregated historical data from other OALP systems
Advanced features of Redshift:
RedShift Spectrum: allows querying data from S3 without loading it into Redshift platform
Federated Query: directly query data stored in remote data sources
Redshift integrates with Quicksight for visualization
It provides a SQL-like interface with JDBC/ODBC connections
By Redshift is a provisioned product, it is not serverless (AWS offers Redshift Serverless option as well). It does come with provisioning time
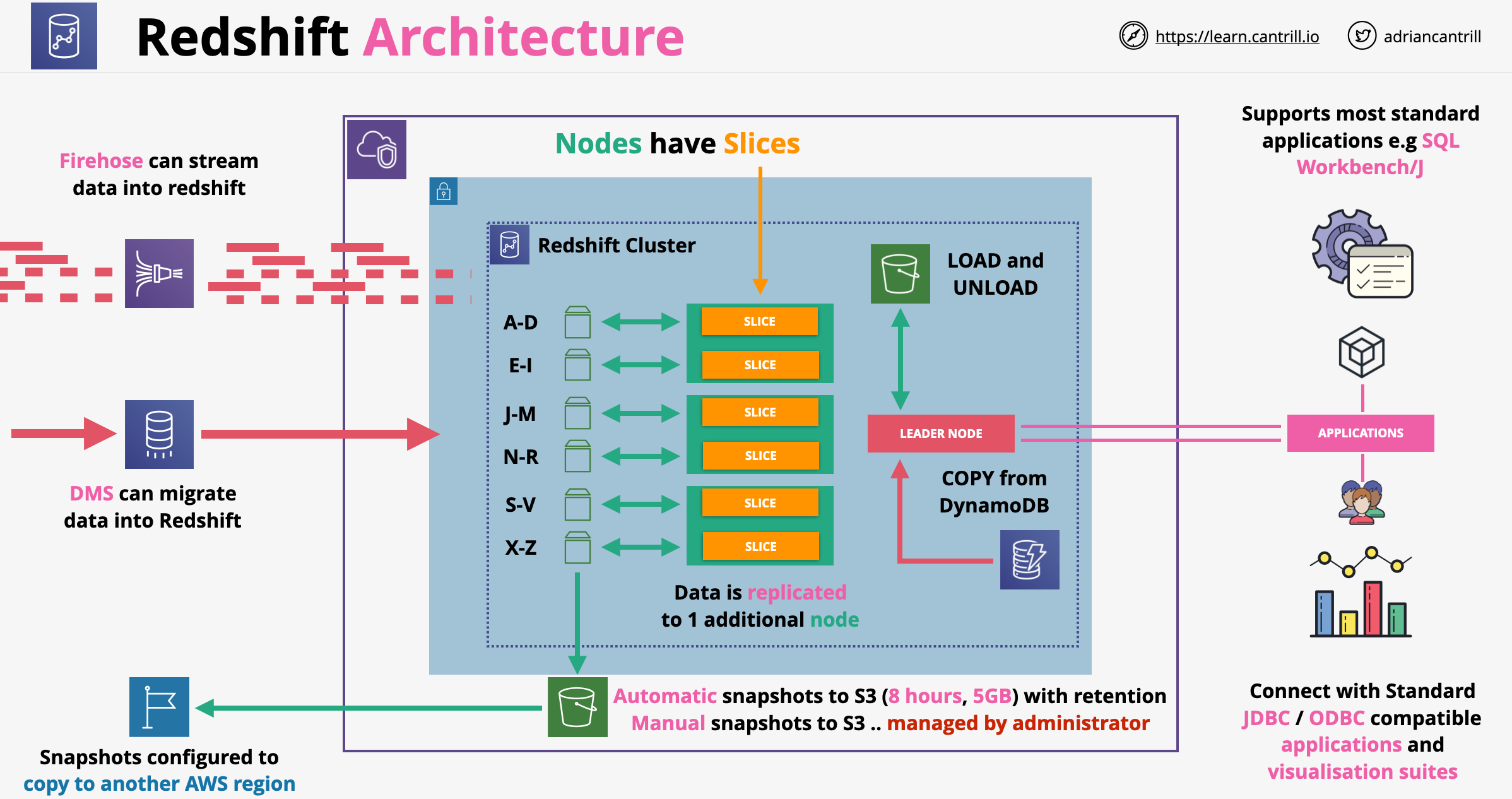
It uses a cluster architecture. A cluster is a private network, and it can not be accessed directly
Redshift runs in one AZ, not HA by design
All clusters have a leader node with which we can interact in order to do querying, planning and aggregation
Compute nodes: perform queries on data. A compute node is partition into slices. Each slice is allocation a portion of memory and disk space, where it processes a portion of workload. Slices work in parallel, a node can have 2, 4, 16 or 32 slices, depending the resource capacity
Redshift if s VPC service, it uses VPC security: IAM permissions, KMS encryption at rest, CloudWatch monitoring
Redshift Enhance VPC Routing:
By default Redshift uses public routes for traffic when communicating with external services or any public AWS service (such as S3)
When enabled, traffic is routed based on the VPC networking configurations (SG, ACLs, etc.)
Traffic is routed based on the VPC networking configuration
Traffic can be controlled by security groups, it can use network DNS, it can use VPC gateways
Redshift architecture:
Redshift Components
Cluster: a set of nodes, which consists of a leader node and one or more compute nodes
Redshift creates one database when we provision a cluster. This is the database we use to load data and run queries on your data
We can scale the cluster in or out by adding or removing nodes. Additionally, we can scale the cluster up or down by specifying a different node type
Redshift assigns a 30-minute maintenance window at random from an 8-hour block of time per region, occurring on a random day of the week. During these maintenance windows, the cluster is not available for normal operations
Redshift supports both the EC2-VPC and EC2-Classic platforms to launch a cluster. We create a cluster subnet group if you are provisioning our cluster in our VPC, which allows us to specify a set of subnets in our VPC
Redshift Nodes:
The leader node receives queries from client applications, parses the queries, and develops query execution plans. It then coordinates the parallel execution of these plans with the compute nodes and aggregates the intermediate results from these nodes. Finally, it returns the results back to the client applications
Compute nodes execute the query execution plans and transmit data among themselves to serve these queries. The intermediate results are sent to the leader node for aggregation before being sent back to the client applications
Node Type:
Dense storage (DS) node type – for large data workloads and use hard disk drive (HDD) storage
Parameter Groups: a group of parameters that apply to all of the databases that we create in the cluster. The default parameter group has preset values for each of its parameters, and it cannot be modified
Redshift Resilience and Recovery
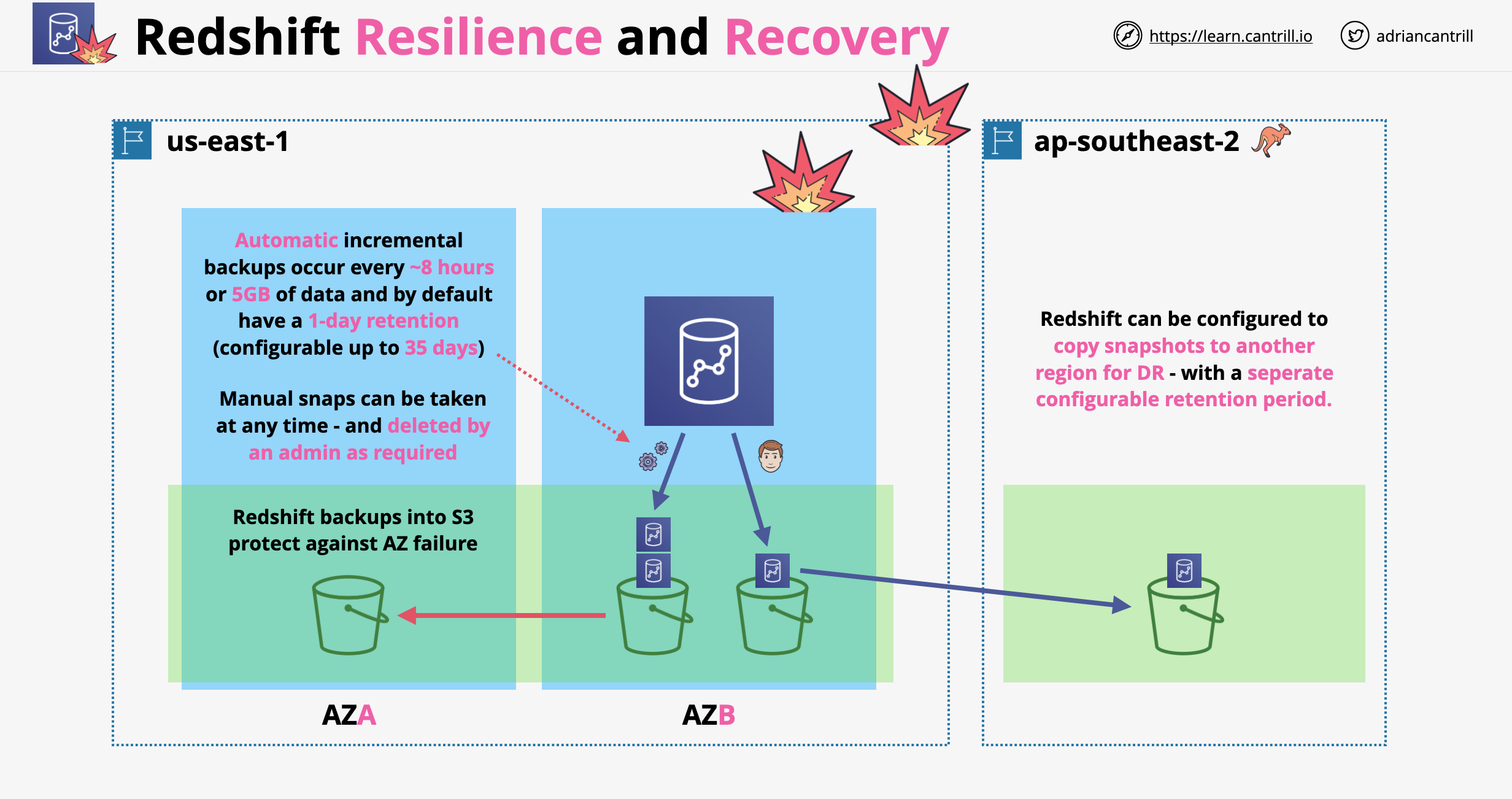
Redshift can use S3 for backups in the form a snapshots
There are 2 types of backups:
Automated backups: occur every 8 hours or after every 5 GB of data, by default having 1 day retention (max 35). Snapshots are incremental
Manual snapshots: performed after manual triggering, no retention period
Restoring from snapshots creates a brand new cluster, we can chose a working AZ to be provisioned into
We can copy snapshots to another region where a new cluster can be provisioned
Copied snapshots also can have retention periods
Amazon Redshift Workload Management (WLM)
Enables users to flexibly manage priorities within workloads so that short, fast-running queries won’t get stuck in queues behind long-running queries
Amazon Redshift WLM creates query queues at runtime according to service classes, which define the configuration parameters for various types of queues, including internal system queues and user-accessible queues
From a user perspective, a user-accessible service class and a queue are functionally equivalent